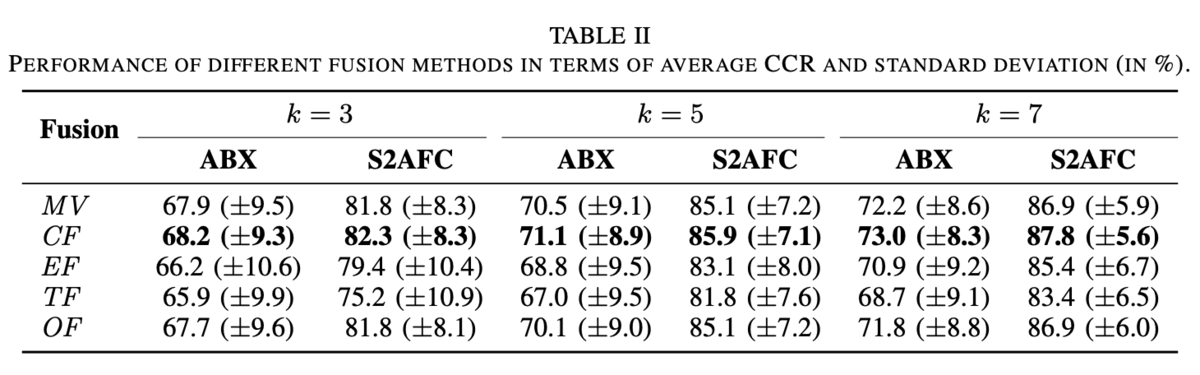
こんにちは!Liquidインフラチームの上原です。
この記事では、Terraformのコードリファクタリングについて解説します。 Terraformを使っていて、コードが増えてきて読みにくい…など、同じ悩みを抱えている方の助けになれば幸いです。
導入
Liquidではインフラに AWS を、インフラ管理に Terraform を使用しています。
Terraformは、AWSなどのクラウドインフラサービスの管理ツールです。インフラ構成をコードで記述すると、それに従ってリソースの生成を実行してくれます。
手間のかかる構築作業を自動化できたり、意図しない設定をすぐに検知・修復できたりと、インフラ運用を安全でラクにしてくれる便利ツールです。
実際のコードはこんな感じ。
# AWS VPC内にEC2インスタンスを構築する # `terraform apply` を実行すると、VPC・サブネット・ENI・EC2インスタンスが生成される resource "aws_vpc" "my_vpc" { cidr_block = "172.16.0.0/16" } resource "aws_subnet" "my_subnet" { vpc_id = aws_vpc.my_vpc.id cidr_block = "172.16.10.0/24" availability_zone = "ap-northeast-1a" } resource "aws_network_interface" "foo" { subnet_id = aws_subnet.my_subnet.id private_ips = ["172.16.10.100"] } resource "aws_instance" "foo" { ami = "ami-12345678901234567" instance_type = "t2.micro" network_interface { network_interface_id = aws_network_interface.foo.id } }
Terraformのコードでは、まずリソースを表すブロックを作ります。VPCなら "aws_vpc" 。
そして、その中に設定を記述します。CIDRブロックやAZ、インスタンスタイプ等々。
vpc_id = aws_vpc.my_vpc.id のように、他のリソースを参照することもできます。
とてもシンプルで見やすいですね!……今のところは。
コード品質
terraformの場合、必要なリソースを1つ1つ並べていけば、とりあえず動くコードにはなります。
しかし、なんとなく想像がつくと思いますが、管理対象が大きくなるにつれコードは肥大化。
やがて様々な問題が…
- 分量が多く、目当てのリソースが見つけられない
- 関連するリソースの記述が分散し、影響範囲を調べるのが大変
- コピペが増え、同じ修正を何箇所にも入れないといけない
もし間違った設定で構築が実行された場合、システムはいとも容易くダウンします。
(もちろん制御機構があるので、致命的な間違いは起きにくいですが)
Terraformのコード品質は、システムの信頼性に直結する重要な要素といえます。
幸いなことに、Terraformには変数・ループ・関数・モジュール等の機能が備わっています。
これらをうまく使って、品質の高いコードにリファクタしましょう!
…Terraformにおけるコード品質って何でしょう?
ここでは、一般的なプログラミング原則に照らして考えてみます。
DRY原則
DRY(Don't Repeat Yourself)原則とは、平たく言えば「繰り返しはやめよう」という考え方です。
もう少し厳密に言うと「システム内ではすべての情報が単一かつ明確に表現されていなければならない」となります。*1
この原則に反した場合、繰り返された情報の整合性を取ることが難しくなります。
例えば、同じ役割を持つEC2インスタンスが複数台稼働しており、それぞれ別のコードで管理されているとします。
resource "aws_instance" "server_1" { ami = "ami-12345678901234567" instance_type = "t3.micro" subnet_id = aws_subnet.my_subnet.id vpc_security_group_ids = [aws_security_group.my_sg.id] tags = { Name = "myserver" } } resource "aws_instance" "server_2" { ami = "ami-12345678901234567" instance_type = "t3.micro" subnet_id = aws_subnet.my_subnet.id vpc_security_group_ids = [aws_security_group.my_sg.id] tags = { Name = "mysevrer" } } resource "aws_instance" "server_3" { ami = "ami-12345678901234567" instance_type = "t3.micro" subnet_id = aws_subnet.my_subnet.id vpc_security_group_ids = [aws_security_group.my_old_sg.id] tags = { Name = "myserver" } }
ある時、セキュリティグループの変更が1台だけ漏れてしまいました。しかし、文法エラーではないためそのまま反映されます。
また、実は1台だけタグに誤字があったのですが、それも誰も気づかず反映されてしまいます。
その結果、特定のインスタンスのみ一部端末から接続できない、集計対象に含まれないといった問題が発生します。
こういった問題、なかなか気づきにくいんですよね。修正作業はもはや間違い探しです。
1つだけタグ名が「myse vr er」になっていたことに気づきましたでしょうか?
ということで、terraformの機能を使って解決していきましょう。
同じリソースを複数台作るだけであれば、「count」を使って台数を指定すれば大丈夫です。
The count Meta-Argument - Configuration Language | Terraform | HashiCorp Developer
locals { number_of_instances = 3 } resource "aws_instance" "server" { count = local.number_of_instances ami = "ami-12345678901234567" instance_type = each.value["instance_type"] subnet_id = aws_subnet.my_subnet.id vpc_security_group_ids = [aws_security_group.my_sg.id] tags = { Name = "myserver" } }
これだけでも「EC2の設定」という情報の繰り返しが消え、いくらかクリーンなコードになります。
さらに「EC2の台数」という情報も明確になりました。台数の増減も「number_of_instances」の値を変えるだけなのでラクです。
しかし、実際にはインスタンス毎に固有の設定を入れたいケースも多いでしょう。
その場合、一例ですが「for_each」を使ってこのような書き方ができます。
「固有設定」と「共通設定」をがそれぞれ1箇所にまとまっていますね。
The for_each Meta-Argument - Configuration Language | Terraform | HashiCorp Developer
locals { instance_settings = { "server1" : { instance_type = "t3.micro" }, "server2" : { instance_type = "t3.small" }, "server3" : { instance_type = "t3.medium" }, } } resource "aws_instance" "server" { for_each = local.instance_settings ami = "ami-12345678901234567" instance_type = each.value["instance_type"] subnet_id = aws_subnet.my_subnet.id vpc_security_group_ids = [aws_security_group.my_sg.id] tags = { Name = each.key } }
では、もう少し複雑な例を考えてみます。
踏み台用のEC2インスタンス(bastion)があります。セキュリティグループを使い、踏み台に接続可能なIPアドレスを制限します。
セキュリティグループに付与できるルールの上限は60なので、IPアドレスが61件以上になった場合は追加のセキュリティグループを作る必要があります。*2
# 記述は一部省略しています resource "aws_instance" "bastion" { ... vpc_security_group_ids = [ aws_security_group.bastion_sg_1.id, aws_security_group.bastion_sg_2.id, ] } resource "aws_security_group" "bastion_sg_1" { name = "bastion-sg-1" ... ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = [ "10.0.0.1/32", "10.0.0.2/32", ... "10.0.0.60/32", ] } resource "aws_security_group" "bastion_sg_2" { name = "bastion-sg-2" ... ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = [ "10.0.0.61/32", ... ] }
このコードは「EC2へのアクセスを許可するIPアドレス」「セキュリティグループの共通設定」の情報が繰り返されており、DRY原則に反します。
実際、IPアドレスが増減するたび60件制限を意識しながら調整するのは面倒ですし、sg_1 と sg_2 の設定がうっかりズレてしまっても防げません。
では、このコードを改修してみましょう。
この例では、terraformの関数もいろいろ使ってみます。
locals { # chunklist : 指定した件数ごとに、配列をさらに分割する関数 # bastion_ip_listは [[1, 2, ... , 60], [61]] という配列になる bastion_ip_list = chunklist([ "10.0.0.1/32", "10.0.0.2/32", ... "10.0.0.61/32", ], 60) } resource "aws_instance" "bastion" { ... # length(local.bastion_ip_list) は 2 # bastion_sg[0].id と bastion_sg[1].id が付与される vpc_security_group_ids = [ for i in range( length(local.bastion_ip_list) ) : aws_security_group.bastion_sg[i].id ] } resource "aws_security_group" "bastion_sg" { for_each = toset( formatlist( "%s", range( length(local.bastion_ip_list) ) ) ) name = "bastion-sg-${each.key}" ... ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = local.bastion_ip_list[each.value] } }
こうすると、IPアドレスが60件を超えるたびに aws_security_group.bastion_sg["0"] aws_security_group.bastion_sg["1"] …とリソースが自動で作られていきます。
「IPアドレス」「セキュリティグループの共通設定」の情報が1箇所に集約されたため、メンテナンスも容易です。DRY原則に照らしても問題ないといえるでしょう。
まとめ
このように、terraformの機能をうまく使えば、より安全で保守しやすい(=品質の高い)コードを書くことができます。
terraformの関数には面白いものが色々ありますので、公式ドキュメントをざっと眺めてみることをおすすめします。
今回取り上げたのは単一のリソースの繰り返しでしたが、複数のリソースからなる構成が繰り返し利用されるケースも多々あります。
その場合、for文よりも module を使ったほうが良いでしょう。module分割によるリファクタについては、次の記事で説明したいと思います!
*1:原文は“every piece of knowledge must have a single, unambiguous, authoritative representation within a system" この記事ではknowledgeを「情報」と訳しています
*2:最大100件まで上限緩和することができます(2022年現在) https://aws.amazon.com/jp/premiumsupport/knowledge-center/increase-security-group-rule-limit/